
Microsoft unveiled a little language model that could give GPT 3.5 a run for its money and work on an iPhone. Is called Phi-3-mini and its main feature is to have considerable performance but small dimensions, which makes it attractive for local installations on mobile devices such as smartphones.
Phi-3-mini has 3.8 billion parameters but it was trained on as many as 3,300 billion tokens.
The parameter of an LLM is a value that the model learns during training, and is regulated by a process called “backpropagation” which involves the calculation of the error between the model’s predictions, the actual output and the regulation of the parameters itself to minimize this error.
The parameters, therefore, serve to identify the relationships between the different words and phrases of the language, allowing the model to generate results similar to human ones and to make accurate predictions. Without these parameters, a language model would not be able to perform natural language processing tasks with a high level of accuracy.
Therefore, generally, the greater the number of parameters (in LLMs we are talking about billions) the greater the model’s ability to relate the different words in the exact way, increasing the predictive agility of an LLM in the construction of a sentence.
But the goodness of a model is also linked to the quantity (and quality) of data used for its training, e.g in the case of Phi-3-mini we are talking about 3,300 billion tokens, that is, words or pieces of words. A considerable number.
Tested successfully on an iPhone 14
In the study published by Microsoft with which Phi-3-mini was announced, through its researchers the company writes that “Thanks to its small size, Phi-3-mini can be quantized to 4 bits so it only takes up about 1.8GB of memory. We tested the quantized model on the iPhone 14 with the A16 Bionic chip, running natively on the device and completely offline, achieving more than 12 tokens per second”.
Open original
The quantization of an LLM is referred to its weights. In an LLM the weights determine the importance of each input in a neural network, and they are also learned during the training process. When the neural network generates tokens (i.e., in the case of LLMs, words and then text), it uses the weights it learned during training to determine which token is the most likely to generate next.
Having quantized weights reduces the precision of these links and consequently the precision of the model, because in effect the amount of information that the model can use to make predictions about the text to be generated is reduced.
However, reducing the weights has two advantages: it allows you to use less RAM and speeds up the mathematical operations required for inference, i.e. the actual use of an LLM to make predictions.
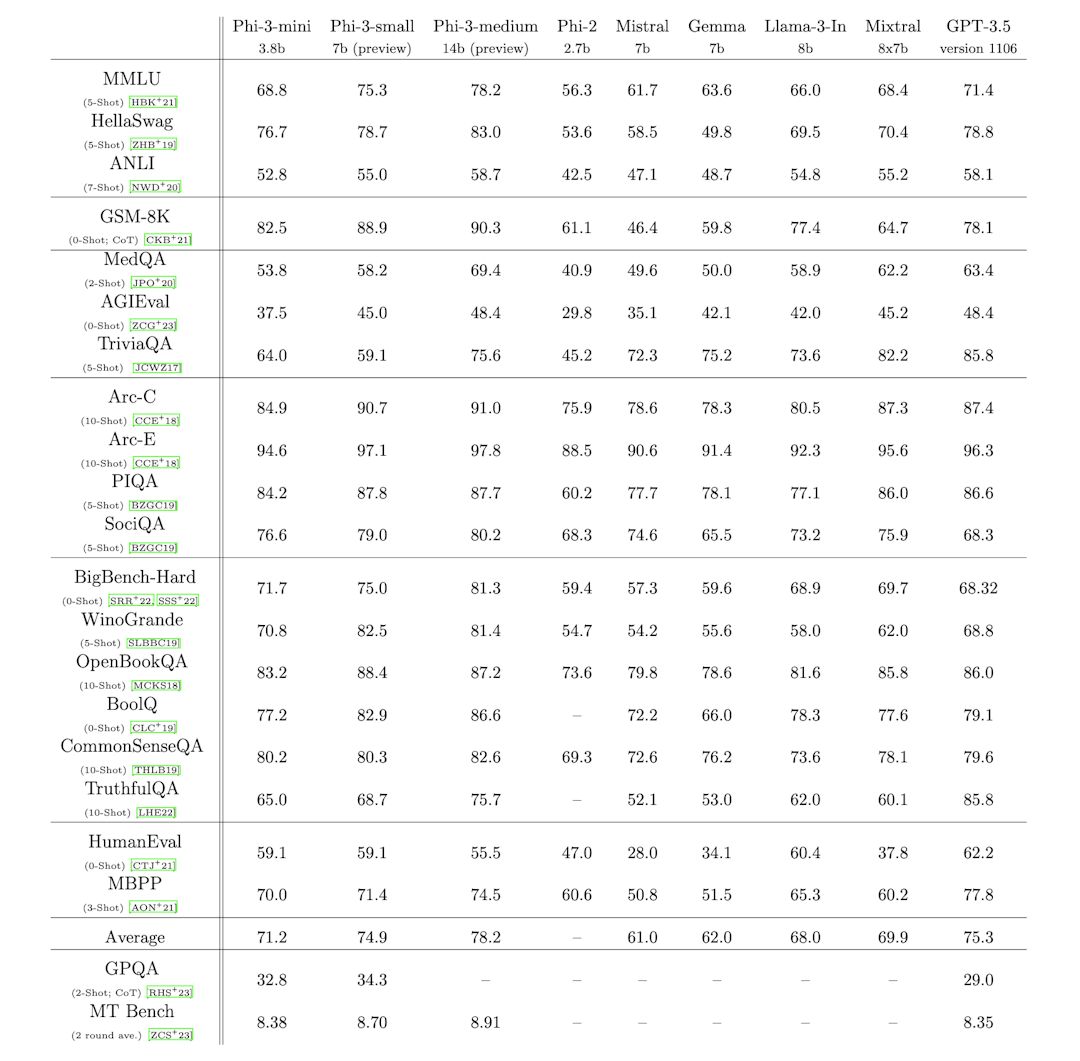
According to Microsoft Phi-3-mini, which has a context window of 4096 tokens (i.e. the maximum amount of tokens the model can process at one time), has overall performance that rivals that of models like the Mixtral 8x7B and GPT-3.5. The latter is the OpenAI model that still gives life to ChatGPT in a free version.
Open original
For Microsoft, the power and innovation of Phi-3-mini is the consequence of that 3,300 billion token training datasetwhich is a scaled version of the one used for Phi-2, composed of significantly filtered web data and synthetic data (i.e. artificially generated by algorithms).
Microsoft is also working on the 7 billion parameter Phi-3-small and the 14 billion parameter Phi-3-medium. Furthermore, it has already managed to extend the Phi-3-mini context window up to 128K (i.e. 128,000 tokens) thanks to the use of an “extender” called LongRoPE.




{kind=link}